| 【python】利用docxtpl和Jinja2生成基于模板的Word文档 | 您所在的位置:网站首页 › python word表格转pandas › 【python】利用docxtpl和Jinja2生成基于模板的Word文档 |
【python】利用docxtpl和Jinja2生成基于模板的Word文档
|
引言 大家是否遇到过需要根据特定模板生成定制化的Word文档的场景?在文档生成和定制化方面,我们经常需要一种灵活而高效的方法来生成基于模板的Word文档。本文通过将 json 中的配置信息以表格的形式展示在Word的案例,介绍如何利用docxtpl、python-docx 和 Jinja2这些Python库来实现基于现有的Word模板生成个性化的文档。 原理在人工使用 MicrosoftWord 编辑文档模板时,可以直接在文档中插入Jinja2的标记,并将文档保存为.docx文件(XML格式)。然后使用 docxtpl 加载这个.docx模板,根据 Jinja2 的语法传入关联的上下文变量,即可生成想要的Word文档。 docxtpl 是基于python-docx和jinja2开发出来的库。docxtpl 的作者开发出它的原因主要是python-docx擅长创建word文档,却不擅长修改。 docxtpl 主要依赖两个包:python-docx 用于读写word文档;jinja2 用于管理插入到模板中的标签。 安装: 代码语言:txt复制pip install docxtpl类 Jinja2 语法此处部分内容摘抄自:https://blog.51cto.com/u_11866025/5659528 4个重要的专属标签正常的Jinja2语法只有%的普通标签,而docxtpl的类语法包含%p,%tr,%tc,%r: 代码语言:txt复制{%p jinja2_tag %} for paragraphs 段落,对应docx.text.paragraph.Paragraph对象 {%tr jinja2_tag %} for table rows 表格中的一行,对应docx.table._Row对象 {%tc jinja2_tag %} for table columns 表格中的一列,对应docx.table._Column对象 {%r jinja2_tag %} for runs 段落中的一个片段,对应docx.text.run.Run对象通过使用这些标记,python-docx-template将真正的Jinja2标记放入文档的XML源代码中的正确位置。 PS:这四种标签,起始标签不能在同一行,必须在不同的行上面,否则无法正确渲染。 例如: 代码语言:txt复制{%p if display_paragraph %}Here is my paragraph {%p endif %}需改写成: 代码语言:txt复制{%p if display_paragraph %} Here is my paragraph {%p endif %}表格处理与合并单元格水平合并单元格在for循环中要合并的单元格内容前面补充: 代码语言:txt复制{% hm %}垂直合并单元格在for循环中要合并的单元格内容前面补充: 代码语言:txt复制{% vm %}准备数据在生成文档之前,我们需要准备要插入到文档中的数据。这些数据可以来自各种来源,如数据库、API或本地文件。根据实际情况,我们可以使用适当的方法获取和准备数据,并将其存储在合适的数据结构中,如字典、列表等。 本次实践,要插入到Word中的数据是多台Linux机器的关键参数配置信息,具体数据示例如下: 代码语言:json复制{ "node_config": { "ip1": { "check_hostnamectl": { "hostname": "node01", "operating_system": "Tencent tlinux 2.6", "kernel": "Linux 5.4.119-1-tlinux4-0010", "architecture": "x86-64" }, "check_cpu_metrics": { "cpu_num": "4C", "model_name": "Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.30GHz" }, "check_physical_cpu": { "physical_cpu": "4C" }, "check_physical_mem": { "physical_mem": "8G" }, "check_nvme": { "nvme_size": "1.80TB*4" } }, "ip2": { "check_hostnamectl": { "hostname": "node02", "operating_system": "Tencent tlinux 2.6", "kernel": "Linux 5.4.119-1-tlinux4-0010", "architecture": "x86-64" }, "check_cpu_metrics": { "cpu_num": "4C", "model_name": "Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.30GHz" }, "check_physical_cpu": { "physical_cpu": "4C" }, "check_physical_mem": { "physical_mem": "8G" }, "check_nvme": { "nvme_size": "1.80TB*4" } }, "ip3": { "check_hostnamectl": { "hostname": "node03", "operating_system": "Tencent tlinux 2.6", "kernel": "Linux 5.4.119-1-tlinux4-0010", "architecture": "x86-64" }, "check_cpu_metrics": { "cpu_num": "4C", "model_name": "Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.30GHz" }, "check_physical_cpu": { "physical_cpu": "4C" }, "check_physical_mem": { "physical_mem": "8G" }, "check_nvme": { "nvme_size": "1.80TB*4" } } } }创建Word文档模板接下来,我们需要创建一个包含占位符的Word文档模板。这些占位符将在后续的文档生成过程中被实际内容替换。使用 Jinja2 的模板语法,我们可以定义占位符和可替换的内容。例如,可以使用 {{ todo }}表示一个占位符。 根据上述 json,输出 Word 表格模板示例如下: 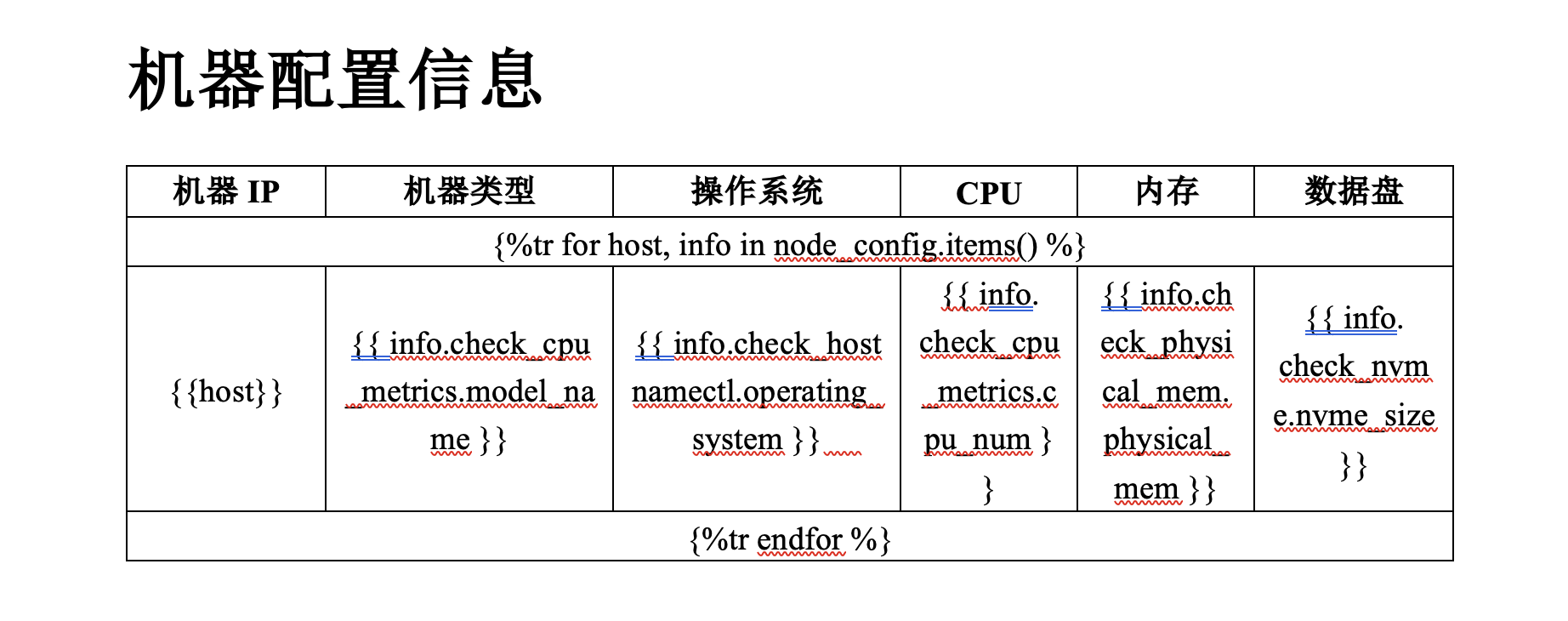 渲染和生成文档 渲染和生成文档现在,我们可以使用 docxtpl 和 Jinja2 来将数据填充到文档模板中,并生成最终的文档。 首先,我们需要加载模板文件并创建一个DocxTemplate对象。然后,我们将数据传递给模板对象,使用render方法渲染文档。最后,可以选择将文档保存到本地文件或直接进行下载。 代码语言:python代码运行次数:0复制import json from docxtpl import DocxTemplate def generate_word(input_path, out_path): # 模板路径 template_path = "/path/to/template.docx" # 加载模板文件,使用 DocxTemplate 类将模板文件转换为 docx 文档对象 docx = DocxTemplate(template_path) # 获取要插入到文档中的数据 with open(input_path, "r") as f: input_data = json.load(f) # 渲染文档 docx.render(input_data) # 保存生成的文档 docx.save(out_path) if __name__ == "__main__": input_path = "/path/to/config.json" out_path = "/path/to/config.docx" try: generate_word(input_path, out_path) print("生成 word 文件成功") except Exception as e: print("生成 word 文件失败: {}".format(e))生成 Word 效果如下: 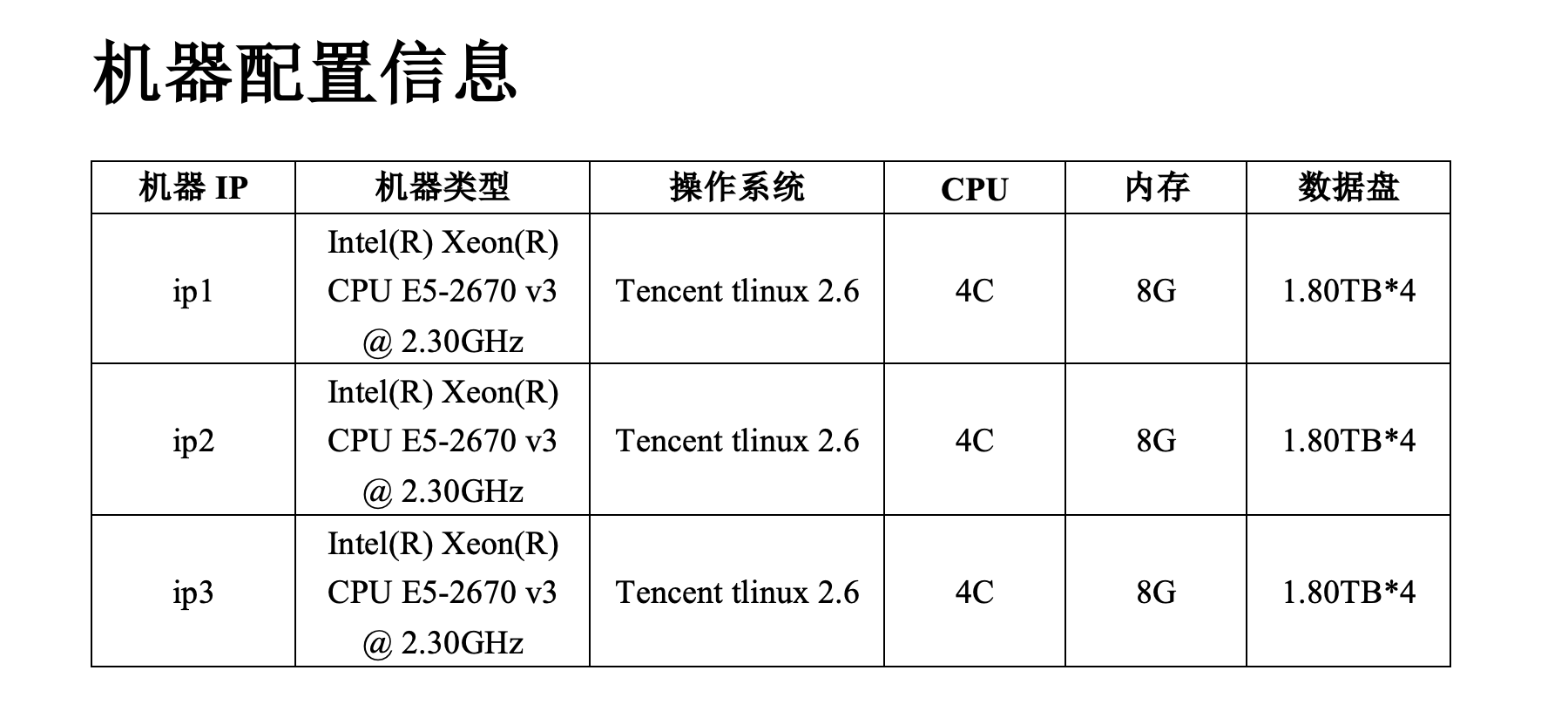 若最终生成的 Word 是由多个.docx模板拼接而成,可以使用下述代码: 代码语言:python代码运行次数:0复制import json import os from docxtpl import DocxTemplate from docx import Document from docxcompose.composer import Composer def generate_word(input_path, output_path): # 定义模板文件路径列表 path_lst = ["/path/to/template-1.docx", "/path/to/template-2.docx", "/path/to/template-3.docx"] # 将模板文件路径列表加载为 DocxTemplate 对象列表 doc_lst = [DocxTemplate(i) for i in path_lst] # 定义一个存储临时文件路径的列表 rm_lst = [] # 读取输入数据文件 with open(input_path, "r") as f: input_data = json.load(f) # 定义一个文档组合器对象 composer = None # 遍历模板对象列表 for index, docx in enumerate(doc_lst): # 指定临时文档路径 docx_path = "{}-test.docx".format(index) # 将临时文档路径添加到删除列表中 rm_lst.append(docx_path) # 渲染模板文档 docx.render(input_data) # 保存渲染后的文档 docx.save(docx_path) # 加载临时文档作为 Document 对象 docx_context = Document(docx_path) # 判断是否为第一个文档,如果是则直接赋值给组合器,否则追加到组合器中 if index == 0: composer = Composer(docx_context) else: composer.append(docx_context) # 保存组合后的文档 composer.save(output_path) # 删除临时文件 for path in rm_lst: os.remove(path) if __name__ == "__main__": input_path = "/path/to/config.json" out_path = "/path/to/config.docx" try: generate_word(input_path, out_path) print("生成 Word 文件成功") except Exception as e: print("生成 Word 文件失败: {}".format(e))总结利用docxtpl和Jinja2可以轻松生成基于模板的定制化Word文档。这种方法简化了文档生成过程,提高了效率。我们可以根据具体需求创建模板,并使用相应的数据进行渲染和生成文档。通过自定义样式和格式,我们能够满足不同的文档需求。 参考jinja2语法docxtpl官方文档docxtpl使用手册 |
【本文地址】